Appearance
半导体
2026-05-14 Samsung Electronics has staged a stunning comeback
In 2024 the South Korean giant apologised for failing to maintain “technological competitiveness” and “falling short of the market’s expectations”.
This month its market value, which has soared by 400% in the past year, hit $1trn for the first time, propelled by furious spending on artificial-intelligence infrastructure.
In the first quarter of 2026 its operating profit rose to 57trn won ($38bn), more than eight times as much as a year before.
Samsung Electronics manages a wide portfolio of products, making everything from fridges to phones. Increasingly, however, its business centres on chipmaking. Semiconductors accounted for 61% of sales and 94% of operating profits in the first quarter.
The number of memory chips Samsung sold in the first quarter was up by about 20% on the preceding three months, but the average selling price rose by 90%. The firm boasts that memory-starved buyers are approaching them to demand long-term purchase agreements. It foresees the shortage lasting well into next year.
A new facility will start mass-producing chips for sale later this year, and the firm will begin building another, which will cost it some $55bn, in July. Yet that factory, known as P5 Fab 2, will not be ready until 2030.
Samsung’s management, perhaps unsurprisingly, continues to display caution. Chipmaking factories are enormously expensive and take years to complete, resulting in a historical cycle of booms and busts. The company will not want a repeat of the last flash-memory boom-bust cycle, when it overbuilt capacity as demand surged, then saw its operating profit fall by half in 2019, notes Jukan Choe of Citrini Research, a firm of analysts.
Meanwhile, Samsung is also expanding its foundry business, which manufactures chips designed by others. A new fab in Texas, catering to American customers, will open this year. The loss-making division has long trailed TSMC, the Taiwanese industry leader, and suffered in recent years from complaints of inconsistent execution. A larger customer base has allowed TSMC to gain scale and know-how, creating a self-reinforcing advantage.
But the AI boom is aiding Samsung’s foundry efforts in two ways. First is that TSMC is booked to the brim. That has already pushed some customers towards Samsung, including Tesla, a carmaker, and Qualcomm, a chip designer. Second is that fat profits in the memory business mean the company has more cash to invest.
Soaring prices have damaged Samsung’s once-thriving consumer-electronics business. Margins are being squeezed in the smartphone division; it may post a loss this year.
On May 11th Kim Yong-beom, an adviser to Lee Jae Myung, South Korea’s president, proposed a “national dividend” to redistribute chipmaking profits to citizens. Mr Lee has since said only excess tax revenue from the chip boom is being considered, not a new tax.
A coalition of Samsung unions is also demanding that 15% of the memory division’s profits be distributed to workers, similar to an arrangement already in place at SK Hynix. They are threatening a multi-week strike beginning on May 21st, which would cost Samsung some 30trn won. (Ironically, union members also lambasted Samsung for failing to capitalise on the AI boom during a strike in 2024.)
2026-05-02 从弃子到王座——AI Infra赛道翻身记
2026-04-30 OpenAI“星际之门”项目是如何拖垮甲骨文的?
2026-04-29 SpaceX, OpenAI and Anthropic are already public companies
If SpaceX—the rocket-maker, internet provider, artificial-intelligence lab and social network controlled by Elon Musk—raises anything close to $75bn, at a valuation anywhere near $2trn, its initial public offering (IPO) will be the financial equivalent of landing on Mars.
Already the enormous gravity of SpaceX is bending public markets. Nasdaq has changed the rules on how quickly firms are included in its index to attract Mr Musk to the exchange.
Most obvious is Tesla. Although it owns just a sliver of SpaceX, the pair share hardware, software and Mr Musk himself.
Some analysts imagine the eventual creation of a consolidated Musk Inc, an industrial Frankenstein’s monster with the body of Optimus, Tesla’s robot, and the brain of Grok, the chatbot developed by xAI, which SpaceX subsumed in February.
Others fret that SpaceX’s listing could undermine Tesla: after all, why would Mr Musk’s adoring retail investors put their money into a carmaker valued at 14 times its sales when they could buy a cosmic creator of superintelligence at 100 times?
Alphabet, the parent of Google, owned 6% of it at the end of last year. This investment, made in 2015, is a large part of the $107bn of private shares on its balance-sheet, the rising valuations of which contributed almost half of Alphabet’s pre-tax profit in the latest quarter.
In March EchoStar, a loss-making telecoms company, improbably shot into the S&P 500 index for no reason other than the $11bn of stock in SpaceX it is set to receive in exchange for selling its spectrum licences. “We have made our bet, and that is with SpaceX,” said EchoStar’s founder after nearly five decades betting on himself.
Consider XMax, a furniture business listed in America with only $17m of annual sales. Until recently it faced the threat of having its shares delisted because they were worth so little. Since September, though, it has aggressively bought into special-purpose vehicles (SPVs) which it says hold shares in SpaceX. Now its market value is an inexplicable $380m.
Jet.ai, a tiny aviation company whose main product appears to be a flight-booking app called “CharterGPT”, attempted to collar the market’s attention in a similar way, though it is still worth less than the $5m of SpaceX shares the firm says it owns through an SPV.
The share price of Mirae, one of its biggest brokers, has almost tripled this year—but mostly because of its small investment in Mr Musk’s empire.
Reports this week that OpenAI has missed some financial targets sent the share price of SoftBank, a Japanese conglomerate that has invested vast sums in the model-maker, down by around 10%.
Meanwhile, Zoom, a video-conferencing company, has mostly escaped the recent massacre of software stocks precipitated by Anthropic’s coding capabilities—because it owns a chunk of Anthropic.
2026-04-27 AI is confronting a supply-chain crunch
The industry’s response has been to pour ever larger sums of money into new infrastructure. On April 20th Anthropic announced a $100bn partnership with Amazon to secure up to five gigawatts (GW) of server capacity, with nearly a fifth due to come online by the end of the year. On April 24th it said that Google would also invest $40bn to help the lab meet its computing needs. On April 27th OpenAI announced that it was reworking its partnership with Microsoft to allow it to distribute all its products through any cloud provider, giving it greater flexibility to tap into computing supply.
The five so-called hyperscalers—Alphabet, Amazon, Meta, Microsoft and Oracle—are investing hundreds of billions of dollars apiece in data centres. Alphabet, Amazon and Oracle have already raised more than $100bn in debt between them this year. To free up cash, Meta recently announced that it would lay off 10% of its workforce, while Microsoft said that it would offer voluntary redundancies to about 7% of its workers.
Adding more capacity, however, is only getting more challenging. In America and beyond, political opposition to the construction of data centres is growing. What is more, the companies making the hardware that fills them—from chips and networking gear to cooling equipment—have been investing far too little to keep pace with demand. The squeeze on capacity, then, looks set to worsen.
In April legislators in Maine voted in favour of a bill to ban the construction of data centres above 20 megawatts until November 2027. Although it was subsequently vetoed by the governor, lawmakers in more than ten other American states are weighing similar measures. According to one count, $156bn-worth of data-centre projects were blocked or delayed last year in America by local opposition and litigation. Other countries, from Ireland to Brazil, are experiencing a growing backlash. Concern over the impact of power-hungry data centres on electricity bills in particular has become widespread—and may intensify further as the war in the Gulf raises energy prices.
Competing AI processors are also getting more difficult to obtain. In April Andy Jassy, Amazon’s boss, said that his company had nearly sold out access to its Trainium2 AI chips. A significant chunk of the capacity of Trainium4, due next year, “has already been reserved”.
The crux of the problem is that companies along the AI supply chain are investing far less than the hyperscalers in expanding their capacity. We examined the planned capital spending this year of the 50 or so largest manufacturers of chips, chipmaking tools, servers, networking gear and cooling equipment, and how it has changed since 2024. Over that period, the five hyperscalers have increased their combined capital spending by 190%, from $234bn to $677bn, whereas the hardware suppliers they rely on have increased theirs by only 45%, from $153bn to $223bn (see chart 2).

Take TSMC, the world’s biggest contract chipmaker and the dominant supplier of cutting-edge GPUs and CPUs. Its most advanced fabs—those making chips that are five nanometres or smaller—are already running flat out. C.C. Wei, its boss, has admitted that supply is “very tight”, but that “there are no shortcuts”: building a new fab takes two to three years. The company plans to spend about $55bn in 2026, up by 34% from a year earlier; analysts expect the figure to rise to $65bn in 2027. As a share of sales, however, its capital expenditure has fallen from around half in 2022 to a third this year.
TSMC’s caution has frustrated its customers. Sam Altman, OpenAI’s boss, has urged the firm to “just build more capacity”. In March Elon Musk, boss of Tesla and SpaceX, announced plans to build a so-called “Terafab” with the modest ambition of churning out more processing power annually than the entirety of the global semiconductor industry today.
Improving software takes months, whereas expanding supply chains takes years. Hardware-makers are wary of over-building and being stuck with idle capacity. The craze for “tokenmaxxing”, then, might soon be cut short.
2026-04-09 South Korea’s AI industrial policy meets the energy shock
Since then South Korea has forsworn dictatorship. But not industrial policy or tortured metaphors: in November Lee Jae Myung, the newish president, pledged to “construct the highway for the AI era”, just as Park “paved the highway for industrialisation”. His plan involves diverting capital from the housing market to industry, especially chipmakers instrumental to the global artificial-intelligence boom, and supplementing this with government cash (see chart 1). The question is whether Mr Lee can pull it off now that, in another echo of the 1970s, South Korea’s imports from the Middle East, which furnishes 70% of its oil and 20% of its natural gas, are disrupted.
To pave this new highway, Mr Lee envisages spending $530bn over two decades on the chip industry. That is nearly equivalent to a year’s worth of all government spending. He has set up a $50bn fund to, among other things, invest in chip companies’ shares. This government backstop is meant to mobilise another $50bn in private capital. A law passed in January allows the government to channel cash directly to firms via another new off-budget vehicle.
The centrepiece of the vision is the world’s largest semiconductor “mega-cluster” in Yongin City, 40km south of Seoul. Samsung Electronics and SK Hynix, the two giants of domestic chipmaking, have between them pledged $700bn to the project by 2047—a third more than their combined global capital spending over the past decade. The idea is to move beyond memory chips, which Samsung and SK Hynix dominate, and also beyond the chipmaking duo, in order to nurture a broader semiconductor supply chain, less dependent on local and foreign oligopolies. As part of its contribution to the Yongin mega-cluster, for example, SK Hynix is building a “mini-fab”, a chip factory where smaller tool and materials firms can test their products. To distribute the resulting economic gains more widely, Mr Lee has also announced the creation of a semiconductor “belt” spanning three southern cities.
The second plank of Mr Lee’s strategy is to encourage “productive finance”. Too much, in the government’s view, has been flowing, unproductively, into housing. Household debt, much of it mortgage-related, is 90% of GDP, compared with 60-70% in America and Japan (see chart 2). Property prices have soared, particularly in Seoul. The problem is made worse by the jeonse system: instead of paying rent, tenants hand landlords an interest-free loan usually worth over half the value of the property, which is returned at the end of the lease period. The sums tenants borrow to pay for jeonse make up 11% of household debt. Landlords often use the cash to buy other properties, further inflating prices.

These aims are now colliding with the energy shock. Even if the ceasefire between America and Iran holds, markets will stay disrupted for months. South Korean natural-gas reserves are days away from exhaustion and it will take weeks for new shipments of the liquefied sort from the Gulf to reach Asia. Chipmakers need to be resupplied with other raw materials, such as bromine used in etching (97% of which comes from Israel) and helium to cool silicon wafers (65% from Qatar). Samsung and SK Hynix can cope; they have a few months’ worth of stocks. The startups Mr Lee hopes will flourish may not.
The energy crisis is also highlighting the tension between Mr Lee’s chip mega-cluster and his “belt”. The government says redistributing the industry to the renewables-rich south of the country is more important than ever. Critics argue that locating high-tech facilities far from the talent hubs and supplier networks that already exist around Seoul, where 80% of Korean chips are made, makes no sense. As a dictator, Park did not have to deal with such opposition. As a democrat, Mr Lee does.
2026-03-18 The next phase of artificial intelligence may require very different processors
Training and inference place different demands on hardware.
Training, in which an AI model is taught to identify patterns in vast amounts of raw data, relies on enormous numbers of calculations being conducted in parallel. Nvidia’s B200 chip, for instance, one of the company’s flagship products, contains more than 16,000 processing units, also known as cores, to perform such operations.
Inference, in which a finished model calls on its training to respond to user prompts, works differently. It unfolds in two stages: prefill and decode.
- During prefill, the model processes the prompt and converts it into small units of text, typically about four characters in English, known as tokens. To speed things up, tokenising different parts of the query can be done in parallel.
- Decoding then generates the response, token by token. To do this, the model relies on its “weights” (relationships between tokens learned during training) as well as previously generated tokens. These weights are stored in the system’s memory.
The need for constant memory access is where modern GPUs fall down. AI processors like the B200 contain small but extremely fast on-chip memory, known as SRAM, as well as a much larger off-chip memory known as DRAM. Accessing DRAM can be ten times slower and consume far more energy than reading SRAM. The problem is worsening. As AI models grow larger and become better at handling long user prompts, their memory demands are rising sharply. A study by Amir Gholami of the University of California, Berkeley, and colleagues finds that over the past two decades computing performance has roughly tripled every few years, whereas off-chip memory bandwidth has improved by a factor of only about 1.6. This “memory wall” has become the main bottleneck in increasing the speed of AI inference.
GPUs rely on software workarounds to cope.
- One approach splits the two stages across different processors.The prefill phase runs on GPUs optimised for high parallel computing power, while decoding runs on separate GPUs designed for fast memory access.
- Another technique is batching, where many queries are processed together. Once the model’s weights are loaded, they can then be used for many queries at the same time, reducing repeated trips to the external memory.
Nvidia’s new chip uses the power of software to give the on-chip memory a boost. The size of the SRAM is around 500 megabytes—tiny when compared with the B200’s 192 gigabytes of off-chip memory. What makes the difference is smart software that choreographs how every piece of data moves through the chip to maximise computation and memory access.
One approach is to simply build a bigger chip. That is the approach taken by Cerebras, an American chip designer. Its latest chip, the size of a dinner plate, contains an enormous 900,000 cores and 44 gigabytes of on-chip SRAM. Because all data movement occurs within the wafer, Cerebras claims its system can run inference up to 15 times faster than conventional designs. For very large models, however, storing all their parameters on SRAM is impractical.
Others are tackling the problem by redesigning how data move through the cores. MatX, a startup founded by former Google chip engineers, builds on an idea used in Google’s tensor processing units (TPUs). These chips rely on what is called a systolic array, a grid of processing elements through which data flow rhythmically, rather like blood pumped through the body. After each calculation the result passes directly to the next unit, bypassing the need to store intermediate results in memory. Traditional systolic arrays, however, are fixed in size. Make them bigger, for larger tasks, and they will often sit idle; make them smaller, and efficiency falls when the larger tasks come through. MatX proposes a “splittable” systolic array that divides the processor into several smaller grids, allocating computing resources differently depending on whether the chip is handling prefill or decode.
A third approach, pursued by d-Matrix, a California-based startup, tries to eliminate the memory wall entirely by having the same components handle both memory and computation. This architecture, known as in-memory computing, promises lower energy use and faster inference.
Others advocate chip designs built around specific algorithms to improve efficiency further. Etched, another Californian startup, is designing a chip custom-built to run transformer models, the algorithms that underpin most LLMs. This specialisation allows the company to strip away hardware needed for other uses and simplifies the software running on the chip. Researchers in China have proposed an even more radical form of specialisation: embedding model weights directly into hardware. In one design from the Chinese Academy of Sciences, these are physically encoded in the layout of metal wires. The authors claim this technique removes the need to fetch parameters from memory, enabling extreme efficiency.
Yet such specialisation carries risks. Designing a new chip typically takes 12–18 months, whereas AI algorithms evolve far faster. A chip built around today’s dominant model architecture could quickly become obsolete if the field shifts.
The chips have yet to fall. Nvidia’s rivals are at different stages. Cerebras is already on its third generation of chips; d-Matrix expects to release its first widely available version this year. Others, including MatX and Etched, remain in development. Nvidia says the Groq 3 LPX will reach the market later this year.
It is easy to see that the GPU conquered training. Inferring what comes next is harder.
2026-03-17 Will South Korea’s epic bull market survive the energy shock?
IN HIS VICTORIOUS campaign for South Korea’s presidency last spring, Lee Jae-myung ran on the promise of “KOSPI 5,000”. As election pledges go, it was admirably specific. It also seemed like a long shot. At the time the country’s benchmark stockmarket index stood at half that, down from a peak of 3,300 or so in 2021. Yet by late January, less than eight months into his tenure, Mr Lee had kept his word. Within another month the KOSPI had burst through 6,000, making the slogan look unambitious. In the 12 months to the end of February the index rose by 138%, leaving all the world’s notable bourses in the dust. Nothing could stand in its way.
In the two trading days after America and Israel attacked Iran the KOSPI plunged by nearly a fifth, now outdoing other major indices on the way down. As a big energy importer, South Korea suffers whenever oil and natural-gas prices rise. With its habitual suppliers in the Gulf paralysed by war, the government has vowed to increase output at coal-fired power plants and cap prices for consumers. Foreign investors had already been cashing out before the war; big domestic ones have started joining in the sell-off. So is the KOSPI bull run kaput?
The index had moved sideways for much of the previous decade (the global post-pandemic boom in 2021 aside). Its constituents were concentrated in stodgy export industries, such as carmaking, shipbuilding, armsmaking and consumer electronics. Many of them were being disrupted by cut-price Chinese competition. And they typically belonged to sprawling and opaque chaebol (family-controlled conglomerates).
The result was a lacklustre return on equity and a persistent “Korea discount” on KOSPI stocks. At the start of 2025 the index traded at a price-to-earnings ratio of just ten, compared with 15 for Japan’s TOPIX (which shares some of the same characteristics) and 25 for the S&P 500, the American blue-chip benchmark (which does not).
Investors’ enthusiasm for K-stocks over the past year can be explained by flaws suddenly turning into virtues. South Korean balance-sheets (heavy on assets) and products (low on obsolescence) typify the hot “HALO” trade. KOSPI firms’ capital intensity was seen as inefficient in a world being eaten by software. It is in vogue as companies are racing to build artificial-intelligence infrastructure, defence budgets are ballooning and the West and China are decoupling in critical products from EV batteries to LNG tankers.
One reason is the KOSPI’s increasing concentration. Just two companies, Samsung Electronics and SK Hynix, account for two-fifths of its market value, up from about a sixth as recently as early 2025, and for more than two-thirds of its one-year returns. It is their soaring profits from memory chips, currently selling like Seoul’s hotteok hotcakes thanks to the AI boom, that have propelled the KOSPI to its heady heights. And these profits are prone to booms and busts like the rest of the semiconductor industry.
Second, the South Korean stockmarket has become more popular with domestic retail traders. The number of active trading accounts and their users’ deposit balances with brokers have both mushroomed. Many are funding their bets with borrowed money. Margin lending, in which investors use loans from brokers, hit a record 34trn won ($23bn) in early March, up from 18trn won the year before. Offshore leveraged exchange-traded funds offering South Koreans beefed-up exposure to Samsung or SK Hynix have seen billions of dollars in inflows this year. All this amplifies gains, but also losses.
2026-03-17 Nvidia is expanding its empire
The transformation is needed partly because Nvidia’s success has attracted competitors. Some are conventional rivals, such as AMD, an American chipmaker that has released decent alternatives to Nvidia’s GPUs. Others are startups spying opportunities. New chip designs are become commercially viable because the need for inference (AI models answering queries) is growing, and the process places a different set of demands on chips from training. According to PitchBook, a data firm, young chip firms raised $17bn in 2025, more than in the previous two years combined.
In the latest financial year just three of these hyperscalers accounted for over half of Nvidia’s receivables, money owed but not yet paid.
Bernstein, a broker, says local suppliers such as Huawei, Cambricon(寒武纪) and MetaX(沐曦) could grow from less than a fifth of China’s AI-chip market in 2023 to more than nine-tenths by 2027.
In December Nvidia paid $20bn to license technology and hire engineers from Groq, a startup specialising in inference chips. On March 16th the company unveiled a new chip using the startup’s knowhow.
Nvidia is also investing in other layers. As AI systems scale, moving data between processors has become as important as the processors themselves. The firm is betting heavily on networking equipment, the technology that links chips together. In its most recent quarter this business generated $11bn in revenue, making Nvidia one of the largest players in the field.
Nvidia has released several families of open-source AI models. These are specialised and aimed at specific industries. That includes Alpamayo for self-driving cars, GR00T for robotics and BioNeMo for biomedical research. They often rank highly on open-source AI leaderboards. Nvidia plans to invest billions to expand its capabilities in this layer of the stack.
Revenue from sovereign AI tripled last fiscal year to more than $30bn, about 15% of Nvidia’s AI sales.
The company is also trying to rely less on the hyperscalers that dominate its customer list. One approach is to push deeper into industry. In carmaking, Mercedes-Benz will soon ship vehicles equipped with Nvidia’s self-driving systems. In pharmaceuticals, Eli Lilly uses Nvidia’s infrastructure and models to accelerate drug discovery. Dion Harris, an Nvidia executive, says the aim is to work more closely with end customers, such as Lilly and Mercedes, to understand their needs and shape the next wave of AI. But Nvidia is not the only one to say it is working closely with clients. Such moves put the firm on a collision course with the hyperscalers, which offer similar services.
Another approach is to create demand through its investments. Nvidia-backed firms, the idea goes, are more likely to buy its chips. Thus the firm is now one of Silicon Valley’s most prolific investors. Since 2020 it has made some 200 investments, committing over $65bn (see chart 2). That includes such big bets as a $30bn investment in OpenAI, and small ones on firms in robotics, software and AI applications.
The firm’s investments also help to secure its supply chain. This March Nvidia put more than $4bn into companies developing optical interconnects, which use light to transfer data rather than wires. Most AI data centres still rely on copper cables to link their equipment.
Nvidia is using its cash pile to strengthen other parts of its supply chain. The semiconductor industry is prone to shortages when demand surges. Supplies of advanced memory—critical for AI chips—are already sold out for this year and for much of next. Nvidia bought most of the memory it will need this year, and part of next, well in advance.

2026-02-12 Arm wants a bigger slice of the chip business
IN THE SEMICONDUCTOR industry, Arm is everywhere and nowhere. Designs from the British-based, American-listed, Japanese-controlled firm sit in almost all the world’s smartphones and most other connected devices. Yet Arm does not sell a single chip. Customers license its designs, tweak them if they wish and produce the chips themselves (or have them made). Arm pockets an upfront licence fee and a slim per-chip royalty. The model has made it ubiquitous. More than 300bn chips built on its designs have been shipped—over 30bn of them last year alone.
Weak demand for smartphones and consumer electronics has weighed on Arm’s shares: since the start of 2025 their price has declined by 2%, even as the benchmark Philadelphia semiconductor index, fuelled by enthusiasm for artificial intelligence, has climbed by 65% (see chart).

Designing a new CPU can cost hundreds of millions of dollars and take 12-18 months. An off-the-shelf blueprint spares customers, such as Apple, much of that burden.
Mr Haas argues that this is only the beginning. As AI workloads shift from training to inference, where models respond to user queries, demand for efficient, general-purpose processors should rise. Much of that work, Arm’s boss expects, will spread beyond data centres into phones, wearables and cars, again favouring CPUs.
Analysts expect revenue this fiscal year to be around $5bn, with half from royalties and the rest from licensing fees.
According to Visible Alpha, a data provider, last year Arm earned royalties of $0.86 per mobile chip, or 2.5-5% of the price.
To illustrate, Mr Haas uses an analogy. For most of its history, Arm sold designs for individual processors. Think of them as “Lego bricks”. Recently it has also started selling blueprints for pre-assembled blocks of processors known as “subsystems”.
One option is to develop custom chips for cloud providers. That has proved lucrative for Broadcom: making bespoke chips for Google and Amazon has helped push its market value above $1.6trn (Arm is worth $135bn). Some analysts think Arm will go further and design and sell its own chips. Rumours suggest that Meta, a social-media giant, will be the first customer.
Either route would bring Arm a bigger cut from its designs, but would entail risks. Creating finished chips, or moving in that direction, would undermine the claim that it does not compete with its customers.
SoftBank, the Japanese conglomerate that owns over 85% of the firm, has been assembling its own chip portfolio, buying Ampere, which makes server processors, and Graphcore, which designs AI chips. In August it bought 2% of Intel for $2bn. Masayoshi Son, SoftBank’s boss, is said to be keen to build an AI champion to rival Nvidia. Mr Haas, who sits on SoftBank’s board, talks up synergies across the group’s chip businesses. But all this may push Arm away from being a neutral supplier of designs.
The big test is whether the revenues of those pouring money into AI rise fast enough to justify the spending. At some point, “the math does need to square”.
A separate concern lies in China, source of a fifth of Arm’s revenue. China’s government is promoting RISC-V, an open-source chip architecture pitched as a domestic alternative to designs from Arm and Intel.
Mr Haas says his biggest worry is whether Arm is investing fast enough to take advantage of the AI opportunity. Chips take years to design and build; AI models evolve in months. Whether the company can move quickly enough is one question. Whether it can make the most of AI without undermining the model that put its designs everywhere is another.
2026-01-12 全球数据中心 | 2026年展望:在租户优先考虑市场投放速度的背景下,容量增长仍保持强劲
国际能源署预计,2026年全球以耗电量衡量的数据中心容量将达到600太瓦时左右,较2025年预计的525太瓦时增长14%,而2025年较2024年436太瓦时的实际耗电量增长20%。

新上线的数据中心容量多数将由**Alphabet Inc.(Aa2/稳定)旗下子公司谷歌、微软公司(Aaa/稳定)、亚马逊(A1/正面)旗下子公司亚马逊云服务(AWS)和甲骨文公司(Baa2/负面)**等大型云服务提供商用于云服务。
2025年,微软、亚马逊、Alphabet、甲骨文、Meta Platforms Inc.(Aa3/稳定)和CoreWeave,Inc.(Ba3/稳定)等美国(Aa1/稳定)六大大型云服务提供商的资本投资接近4,000亿美元,2026年和2027年分别有望达到5,000亿美元和6,000亿美元。
实力雄厚的大型科技企业的这些庞大投资继续推动整个数据中心价值链和AI生态系统的快速增长,从而支持我们对未来5年全球数据中心相关投资至少达到3万亿美元的预测(图表2)

数据中心的发展仍由美国最大市场的新建项目主导。2026年上线容量仍将主要集中在一线市场附近,但鉴于新开发项目的规模以及大型云服务提供商倾向于集中式布局,新的市场可能会迅速涌现,例如在俄亥俄州哥伦布(Aaa/稳定)、亚特兰大(Aa1/稳定)以及德克萨斯州(Aaa/稳定)的达拉斯(A1/负面)、沃斯堡(Aa3/稳定)、圣安东尼奥(Aaa/稳定)和奥斯汀(Aa1/稳定)。德克萨斯州和中西部偏远地区也出现了快速增长,计划建设的AI工厂在产能上最终可能超过国内部分一线市场的规模。
加拿大的开发项目主要集中在多伦多、温哥华和蒙特利尔等大都市地区。
截至2025年底,欧洲的数据中心开发商计划交付创纪录的871兆瓦新增容量,较2024年增长34%。这一新增容量中近四分之三集中在五大市场,统称FLAPD,分别为法兰克福、伦敦、阿姆斯特丹、巴黎(Aa3/负面)和都柏林。我们预计2026年和2027年FLAPD市场每年新增容量约500兆瓦。欧洲正在加快扩展AI基础设施,新增6家AI工厂,使工厂总数达到19家,分布在16个欧盟(Aaa/稳定)成员国。这些新建工厂将与现有的13家共同构建互联的高性能计算网络,旨在加速AI模型和应用的开发、测试及规模化。此次扩张是欧盟战略的重要组成部分,目标在于强化数字主权并降低对非欧洲技术体系的依赖。
巴西(Ba1/稳定)的“数据中心服务特别税收制度(ReData)”、墨西哥(Baa2/负面)的“墨西哥计划”、智利(A2/稳定)的“国家数据中心计划”,以及阿根廷(Caa1/稳定)的RIGI框架为大量大型云服务提供商项目提供了支撑。
在多数市场,电力供应仍是新建数据中心面临的主要制约因素,公用事业公司和独立发电企业正全力应对这次百年一遇的电力需求激增。正如我们预期,随着数据中心规模不断扩大,它们越来越多地采用场内用户侧(“表后”)发电方案,或使用专门满足自身需求的邻近发电设施。虽然用户侧发电方案可以加快获取新增发电能力,但这类方案通常需要建设超出日常需求的容量,以应对电力需求意外增长或维护工作导致个别涡轮机或电厂暂时停运等突发情况。电网接入的漫长延误往往超过数据中心的建设周期,迫使部分新建数据中心在接入电网之前使用临时场内电源。
美国:将会建设更多新的发电设施,包括燃气电厂和可再生能源项目,以及与数据中心毗邻布局的用户侧发电设施,这些设施专门用于为数据中心供电。这些燃气电厂大多将位于主要天然气产地附近,例如德克萨斯州的二叠纪盆地、墨西哥湾沿岸,以及宾夕法尼亚州(Aa2/稳定)和俄亥俄州的页岩气矿区。
欧洲:电网相关的制约是FLAPD市场中的重要因素,同时该市场还面临电力供应受限、严格的规划政策以及适宜土地稀缺等挑战。虽然可再生能源在欧洲发电结构中的占比高于其他地区,但欧洲的电价通常也高于其他地区。在难以满足欧洲FLAPD市场需求的情况下,开发商正加大在瑞典(Aaa/稳定)、挪威(Aaa/稳定)和冰岛(A1/稳定)等北欧国家,以及在西班牙(A3/稳定)、葡萄牙(A3/稳定)和意大利(Baa2/稳定)等南欧国家的布局
铜矿和稀土金属开采企业以及关键冷却和电力相关设备制造商正谨慎提高产量,以满足数据中心带来的需求。但新增产量仍不足以抑制2026年的价格上涨。因此,新建数据中心的建设成本高于同类市场的既有项目,从而推高租户的租金。
过去几年,美国主要市场的超大规模数据中心的租金大幅上涨,这既反映了强劲需求,也体现了新投运设施较高的成本。据datacenterHawk通过FactSet发布的数据,在弗吉尼亚州北部这个全球最大的数据中心市场,容量超过4兆瓦的超大规模数据中心的月租已从2024年的每千瓦110-150美元上涨至2025年的每千瓦130-190美元。这意味着同比涨幅达到18%-27%。在此之前,2024年超大规模数据中心的租金较2023年平均上涨了13.5%。在增长迅速的亚特兰大市场,相关数据显示,2023年-2025年平均租金累计上涨近39%。数据中心的租金通常每年上涨2%-3.5%,因此,2025年-2027年投运的超大规模数据中心的续租成本将低于之后投运的同类设施。
虽然建设进度延误且成本上升,但当前的市场环境仍促使租户在设施可用时直接接受交付,而不是严格行使租赁合同中通常较强硬的权利。一旦市场供需趋于平衡,租户接受设施的倾向可能发生变化,但我们预计多数市场在未来几年内仍难以实现这一平衡。随着数据中心数量大幅增加,以及越来越多经验不足的新运营商进入市场,我们预计未来披露的运营问题将持续增加。随着时间推移,新增的供应链容量可能有助于抑制价格上涨,并改善数据中心开发、运营和改造的经济效益。
我们预计将出现更多具备积极信用结构特征的加密矿企融资,以及采用分期偿还债务、无续租风险的大型项目融资。一些公司正在为专门服务于AI计算工作负载的“新云”(neocloud)提供商开发数据中心容量,例如比特币矿企Terawulf Inc.和AI云公司Fluidstack Ltd的合资企业拥有的Flash Compute LLC(Ba3/稳定)、TeraWulf的全资间接子公司WULF Compute LLC(Ba2/稳定)和比特币矿企Cipher Mining Inc.的全资间接子公司Cipher compute LLC(Ba3/稳定)。比特币矿企通过利用其现有的电网接入渠道可加速大型云服务提供商的市场投放速度。但是,其数据中心项目往往位于非核心市场,这些地区的低电力成本从长远来看可能不足以吸引数据中心租户。虽然这些项目目前对AI模型训练具有重要价值,但其用于推理的能力可能更有限,直到新技术能帮助降低延迟。
随着更多美国数据中心项目完工,其初始融资将开始在资产支持证券(ABS)、商业住房抵押贷款支持证券(CMBS)和私募信贷市场进行再融资。ABS和CMBS市场继2025年发行量达到空前水平之后,2026年将继续创下新高,因此新融资规模和集中度将会提高。2025年美国单一资产/单一借款人(SASB)数据中心CMBS债务发行总额约为110亿美元,相较2024年仅30亿美元的规模大幅增长。我们预计2026年数据中心SASB CMBS发行将进一步增长,但机构投资者对房产类型和租户集中度的限制可能会决定其扩张的程度。美国ABS市场2025年发行额约为150亿美元,受数据中心建设贷款和到期ABS定期票据的再融资推动,美国发行规模在2026年可能大幅增长。由私募股权支持的公司仍将是数据中心ABS交易的最常见发起人。此外,随着全球数据中心开发商和业主在其他地区复制其成功的美国数据中心融资经验,我们预计2026年欧洲将出现新的数据中心ABS融资,亚太区也可能出现首个此类融资。
GPU是AI超大规模数据中心建设的最大单项资本支出。据我们了解,租户通常每4年更换一次内部服务器,以满足大语言模型训练等最前沿的使用需求。因此,AI数据中心包括GPU在内的计算设备成本可能是设施建设初始成本的数倍。
与大型科技公司签约、在运行最新GPU方面经验最丰富的GPU即服务(GPU-as-a-service)提供商越发能够将这些设备的使用年限延长至其初始生命周期以外。
2026-01-08 The AI frenzy is creating a big problem for consumer electronics
Excitement over the prospect of clever new devices powered by artificial intelligence is as strong as ever. Yet by gobbling up memory chips, which are essential for everything from smartphones and personal computers (PCs) to gaming consoles and cars, AI is creating a supply crunch for electronics-makers.
Jeffrey Clarke, chief operating officer of Dell, a manufacturer of computers, has called the situation “the most unprecedented mismatch in demand and supply” he has ever seen. Xiaomi, a Chinese smartphone-maker, has warned of delays and rising prices. Analysts predict that prices for PCs could jump by 15-20% in response. IDC, a data firm, reckons that if the situation persists, global smartphone shipments could fall by as much as 5% this year, and PC sales by roughly twice that.
Semiconductors are a cyclical business, prone to swing from surplus to shortage.
The rapid construction of data-centres has sent demand for HBM soaring. Producing it is resource-intensive: HBM requires three to four times as many silicon wafers as standard DRAM.
Supply is highly concentrated. Just three firms—SK Hynix and Samsung Electronics of South Korea, and Micron of America—rake in more than 90% of global DRAM revenue. All three are switching capacity to HBM, which will account for half of global DRAM revenue by the end of the decade, up from 8% in 2023, reckons Bloomberg Intelligence, a research group. HBM typically yields operating margins of 50% or more, compared with 35% for standard memory. Investors have rewarded the strategy. Since the start of 2025 the trio’s share prices have risen by an average of 200% (see chart 1).

But the flip side is that more basic memory chips, which account for 15-40% of the cost of smartphones and PCs, are becoming scarcer and costlier. The price for the DRAM found in most consumer electronics, known as DDR4, has risen by 1,360% since April 2025 (see chart 2).

The impact will be uneven. Apple, with its pricey i-gadgets and enormous scale, will be better placed to absorb higher costs and secure supply. Samsung will benefit from in-house memory production.
Asus, a Taiwanese PC-maker, raised prices for its laptops on January 5th. Xiaomi has said memory costs will have a “big impact” on margins. Carmakers may feel the strain most: as vehicles incorporate more electronics, the amount of DRAM per car is growing rapidly.
Relief will come slowly. Memory-makers plan to spend about $61bn on capital investment for DRAM this year, a 14% increase on 2025. But new capacity takes as long as two years to come online. Moreover, 60-70% of planned investment is earmarked for HBM, reckons Jukan Choi of Citrini Research, a firm of analysts. Chinese producers, which have become big suppliers of basic DRAM in recent years, are unlikely to plug the gap; they too are focusing on HBM. For now, only an unravelling of the AI boom would ease the shortage. Consumers may soon feel the pain.
2026-01-06 America’s missing manufacturing renaissance
Nearly a year on, however, the Trumpian manufacturing renaissance is conspicuous by its absence. The manufacturing contraction is now entering its third year, and factories have continued to shed jobs; employment fell by 0.6% in the year to November (see chart 1). And it is not just that Mr Trump’s actions are failing to revive American manufacturing. Under the hood, there are signs that they are actively hurting it.

Part of the problem is high interest rates. American industry fell into recession in early 2023, soon after the Federal Reserve sharply raised rates to combat inflation. Manufacturing, with expensive and often debt-financed kit, is especially sensitive to such changes. Mr Trump is keen to see looser monetary policy; America’s continuing high rates mostly reflect robust economic growth and vast rate-insensitive AI spending. All the same, his policies have not helped. High deficits and threats to the independence of the Fed have made American debt less desirable for investors, and thus lifted borrowing costs.
Moreover, his tariffs have injected uncertainty into the economy. For a manufacturing sector that sends nearly a quarter of its output abroad, this is a significant problem. Many inputs also come from abroad—think of industrial chemicals used in adhesive, coatings and plastics for cars or active pharmaceutical ingredients for medicines. Indeed, surveys suggest that export orders and import volumes for manufacturing have contracted markedly since Mr Trump announced high tariffs on “Liberation Day” in April, one that goes beyond the wider weakness in manufacturing (see chart 2). Factory bosses report difficulty making long-term plans.

Another way to see these costs is to look at the one sort of manufacturing that has been on a tear: computer equipment, especially semiconductors (see chart 3). Demand for chips has leapt owing to the data-centre boom. Notably, however, computer parts have also received exemptions from Mr Trump’s tariffs, points out Joseph Politano of Apricitas Economics, a newsletter. Semiconductors have been carved out from Mr Trump’s “reciprocal” tariffs on specific countries. More recently, the president has also watered down the export-control regime designed to deny China chips used to train the most sophisticated AI models. This rare free-trade turn seems to have provided a spur to the industry.

2025-09-09 亚洲半导体业 | 尽管中美关系紧张且供应链存在风险,但亚洲仍将保持全球芯片制造领先地位

2025-08-21 Japan storms back into the chip wars
Founded in 2022, the firm opened its massive semiconductor factory, or “fab”, last year in Chitose, a small city on Hokkaido, Japan’s northernmost main island. In December Rapidus became the first Japanese entity to acquire an extreme ultraviolet lithography (EUV) system from ASML, the Dutch company that makes the unique devices; Rapidus had the complex up and running within months. In mid-July, Mr Koike announced the successful pilot production of two-nanometre (2nm) transistors, the thinnest, most advanced chips yet.
In the boldest industrial policy push in a generation, the Japanese government ploughed ¥3.9trn ($27bn) into support for semiconductors between early 2020 and early 2024. As a share of GDP, that amounts to a bigger commitment than America made to its semiconductor industry through the CHIPS Act. Japan wants both to revive its domestic champions and to attract foreign ones, such as TSMC, the Taiwanese semiconductor giant, which now makes chips in southern Japan.
Japan once dominated the semiconductor industry. In the 1980s, Japanese firms accounted for more than half of the global market, and an even bigger share of the cutting-edge chips of the time. But trade friction with America led to limits on Japanese chip exports, creating an opportunity for rivals in Taiwan and South Korea. Japanese companies also struggled to shift to an era of increasing specialisation in semiconductor production. Whereas some Japanese firms retained strong positions in the materials and equipment necessary for making semiconductors, from coating chemicals to silicon wafers themselves, they fell behind in cutting-edge manufacturing. By 2019, Japan accounted for less than 10% of the world’s semiconductors.
The Japanese government came to see this state of affairs not only as a commercial disaster, but also as a national-security risk. Supply-chain disruptions during the pandemic helped raise public awareness of the crucial role chips play in modern life. The war in Ukraine fuelled fears of Chinese designs on Taiwan—and highlighted the risk of depending on a single firm there for most of the world’s high-end chips. The emergence of generative artificial intelligence (AI) has only heightened the strategic importance of semiconductors. Japan’s latest National Security Strategy, released in 2022, explicitly sets a goal of strengthening “next-generation semiconductor development and manufacturing bases”.
Japan’s semiconductor strategy consists of two main pillars. First is indispensability, which means, in effect, “being influential over others”, says Mireya Solís of the Brookings Institution, an American think-tank. The idea is that if Japan can control parts of a long supply chain it can leverage that interdependence to keep others (ie, China) from weaponising their control over certain inputs.
The second pillar is autonomy, or having domestic production capacity. “The world will be divided into two groups: countries that can supply semiconductors and countries that buy them,” says Amari Akira, a former lawmaker with the ruling Liberal Democratic Party (LDP) who led semiconductor policy. “The countries that supply will be the winners, and the countries that buy will be the losers.”
Big subsidies helped entice TSMC to set up shop in Kyushu. Its first fab there produces chips of 12-28nm—the most advanced type of semiconductor to be produced in Japan so far, but still well behind its state-of-the-art models. The firm has already announced plans to build a second facility for even higher-end logic chips there; talks about a potential third fab are reportedly under way. TSMC’s arrival has enticed suppliers and partners to expand on Kyushu, which has positioned itself as “Silicon Island”.
Micron, an American memory chipmaker, has also received more than $1bn in subsidies to expand its chipmaking facilities in Hiroshima.
Meanwhile Samsung, a South Korean electronics giant, is building a cutting-edge research facility in Yokohama, south of Tokyo.
Another nascent ecosystem is emerging around Rapidus. The firm is the highest-risk and highest-reward bet of the bunch. Born of a partnership with IBM, which developed a new method for making next-generation transistors, a type of electrical component, Rapidus hopes to leapfrog across a generation of semiconductor engineering and catch up with global pace-setters. It has attracted investment from a consortium of eight blue-chip Japanese firms, including Sony, Toyota and SoftBank(另外5家:铠侠(Kioxia)、日本电装 (Denso)、日本电气 (NEC)、日本电报电话 (NTT)、三菱UFJ银行 (MUFG Bank)) . The government has also bankrolled much of the initial cost, to the tune of ¥1.72trn ($12bn) through early 2025.
The success of Rapidus hinges on meeting three big challenges, says Ota Yasuhiko of Hokkaido University. First is cultivating enough talented cadres. Universities across Japan are launching programmes to train a new generation of semiconductor engineers. But in the meantime, Rapidus has had to rely largely on older specialists who came of age during Japan’s first chip boom; the average age of its recruits was initially over 50. Roughly 150 top engineers were sent to train at IBM’s research facility in New York.
Another challenge is developing a sustainable business model. Samsung and TSMC are advancing towards 2nm chips of their own, and have established relationships with the buyers of high-end semiconductors. Rapidus is positioning itself as a boutique option, able to make smaller lots of specialised chips, rather than large batches of one-size-fits-all offerings. “We have no intention of directly competing with TSMC—the markets are different,” Mr Koike says. He is counting on generative AI becoming a tailwind, boosting overall demand for chips and increasing interest in offerings that can improve efficiency and reduce power consumption.
But first Rapidus must make the leap to mass production, which the firm aims to begin in 2027. While the successful pilot wafer is an encouraging sign, the true test will be whether Rapidus can make lots of them of the quality necessary to be commercially viable. The production process for such semiconductors is closer to handmade crafts than to assembly-line widgets: engineers must constantly adjust equipment to maintain correct parameters.
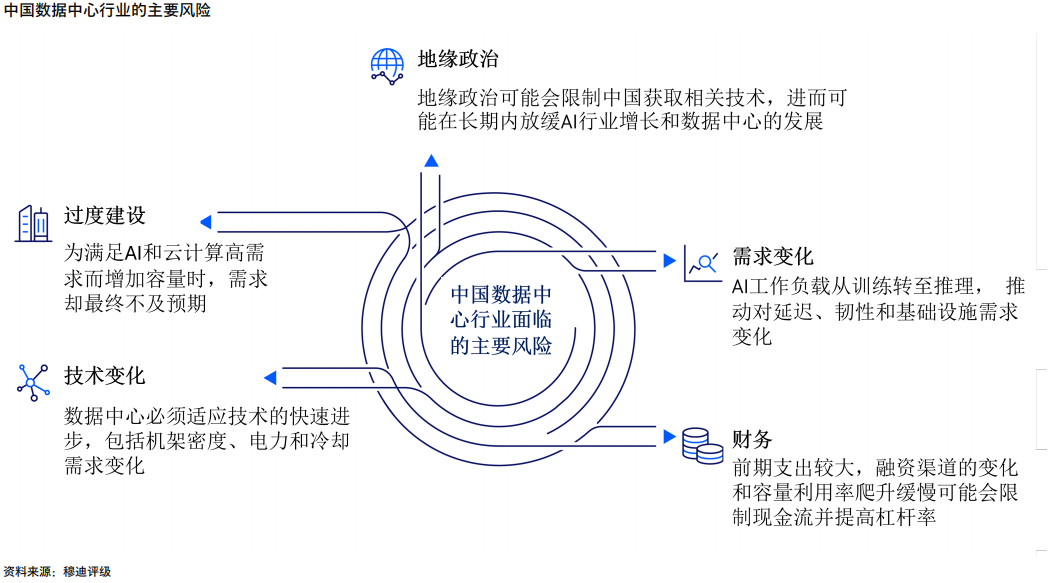
2025-08-04 中国数据中心 | 人工智能和地缘政治推动中国数据中心建设
市场上主要有两类设施:为多个租户提供共享基础设施的零售托管数据中心,以及通常长期租给单一租户的大型云服务数据中心。
由于低延迟需求等因素推动人口稠密地区附近数据中心的发展,京津冀、长三角以及包括中国香港特别行政区(Aa3/稳定)和中国澳门特别行政区(Aa3/负面)在内的粤港澳大湾区等主要经济区在数据中心容量中的占比较大。
2025年2月,阿里巴巴宣布计划未来3年向AI和云计算相关项目投资人民币3,800亿元,超过过去10年其在该领域的总投入。同样,腾讯表示,2025年其资本支出占收入的比例将处于两位数低段,2024年这一比例为12%,而2023年仅为4%。
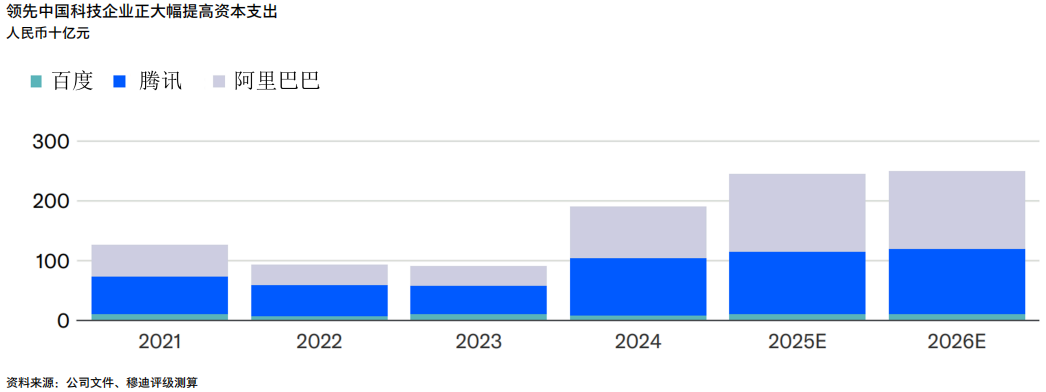
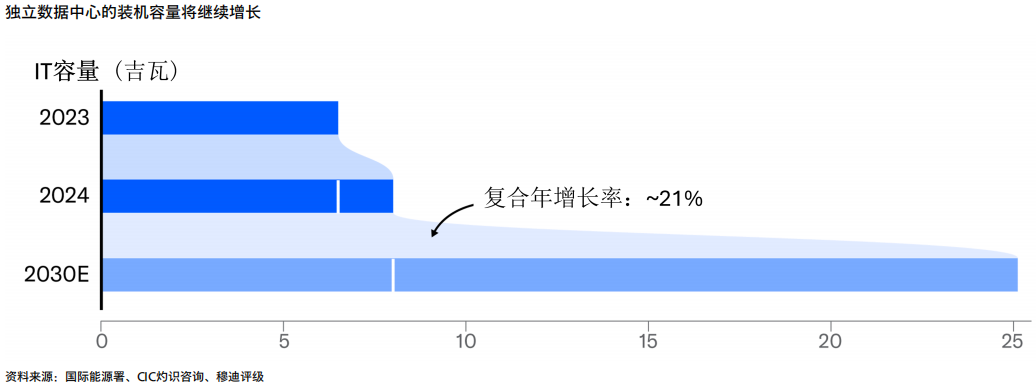
根据国际能源署数据和我们的测算,到2030年,中国的独立数据中心总容量(包括大型云服务提供商,托管和边缘数据中心)预计将较2024年底的8吉瓦左右翻一番以上(图表3)。多数新增容量预计将预租给信用良好的租户,从而缓解运营商和投资方的开发和租赁风险。
美国推出的 “清洁网络计划”实质上禁止了新铺设直接连接中美两国的海底光缆,这反映了美方限制中国接入关键互联网基础设施的更广泛战略。
**房地产投资信托基金(REITs)**作为一种融资机制也越来越受关注。2024年11月,世纪互联与大家投资控股有限责任公司联合推出pre-REIT基金,最初将主要投资于江苏太仓的IDC园区。2025年4月,万国数据通过私募REIT将部分投资组合变现,获得人民币5亿元的前期资金,并剥离了人民币12亿元的债务和其他净负债。2025年6月26日,上海证券交易所批准了万国数据的C-REIT首次公开发行,规模约人民币19亿元,涉及出售昆山一家资产稳定的数据中心项目公司。

例如,万国数据的子公司DayOne Data Centers Limited在新加坡、马来西亚、印尼、泰国和日本均有业务。WinTriX DC Group子公司Bridge Data Centers也在马来西亚和泰国等市场迅速扩张(图表6)。

马来西亚和印尼直接受益于新加坡的需求外溢,这主要是由于新加坡最近3年暂停数据中心容量扩张以及该国的土地供应限制。马来西亚对数据中心的投资有所增加,尤其是在南部柔佛地区。除了中国数据中心运营商之外,其他几家大型云服务提供商也在寻求扩大马来西亚的容量。微软公司(Aaa/稳定)于2024年6月购置土地,计划用于发展新的数据中心;Alphabet Inc. (Aa2/稳定)和亚马逊(A1/正面)也承诺在马来西亚数据中心和云服务领域分别投资20亿美元和60亿美元。
2024-10-24 Memory chips could be the next bottleneck for AI
2023-05-25 Asian businesses are being dragged into the chip war
UNLIKE LOGIC chips, which process information, memory chips, which store it, looked less vulnerable to the Sino-American techno-tussle. Such semiconductors are commodities, less high-tech than microprocessors and so less central to the great-power struggle for technological supremacy.
That changed on May 21st, when the Chinese government banned memory chips made by Micron from critical-infrastructure projects. The restriction hurts the American chipmaker, which last year derived 11% of its revenue from mainland China. It also opens up a new front in the transpacific chip war—one which the countries that are near China but allies of America are being roped into.
By opening a gap in the market, the ban creates an opportunity for the world’s two biggest memory-chip makers, Samsung Electronics and SK Hynix, both from South Korea. They made 16% and 44% of their respective sales in China in 2021.
That is what investors seem to have concluded: Samsung’s share price is at its highest since April 2022; SK Hynix’s was last this lofty in August.
South Korea exported $156bn-worth of goods, equivalent to 9% of its GDP, to the country in 2022, and imported roughly the same amount. That makes China its largest trading partner by some distance.