Appearance
X Square Robot 自变量机器人
文章
从Chatbot 到 Physical AI
2022年末,ChatGPT横空出世,AI、大语言模型开始被所有人关注。2023年,所有人都涌向了大语言模型,被称为“大语言模型(LLM)“的元年。
到现在,只有3年多一点的时间,大语言模型已经融入到了我们的生活之中,向ChatBot提问,和ChatBot聊天,使用AI画图,写代码,我们已经离不开AI了。
但像Chatbot AI这种AI,处理的还是符号、语言、像素点等虚拟世界的东西,那么怎么让AI能够感知物理世界,在物理世界里完成各种任务,是目前技术、商业领域都在研究的热点。
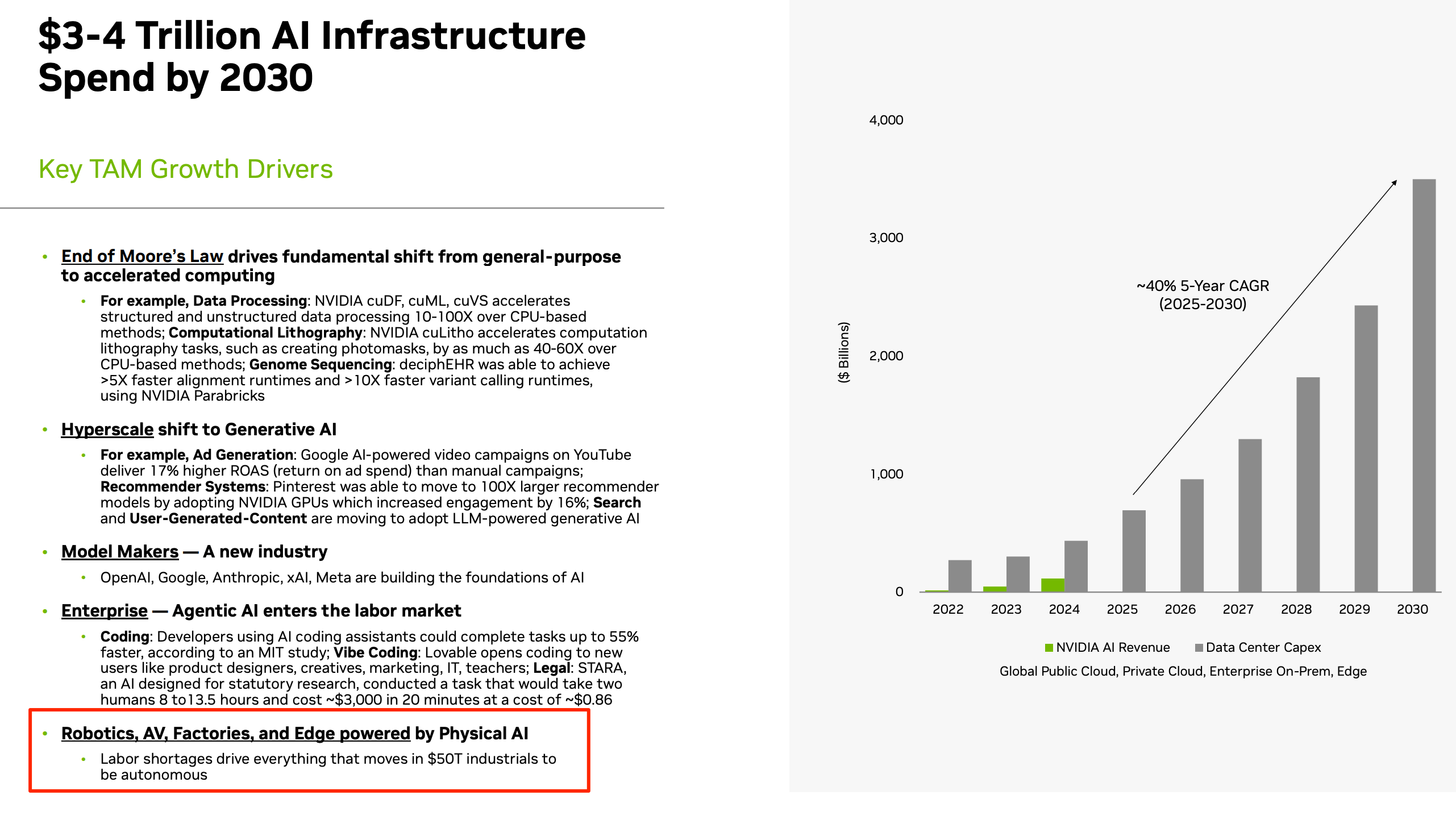
英伟达在2025年10月份的路演中,预计2030年,AI基础设施的支出要达到3-4万亿美元,而驱动AI基础设施投入增长的一个关键领域,就是物理AI(Physical AI)。
物理AI(Physical AI)则要求模型理解真实物理世界的规则,具备空间感知能力,并能产生物理位移或精细的操作指令.这意味着模型必须能够处理连续的物理反馈——如重力、摩擦力、阻力以及不可预测的环境噪声。
具身智能
Physical AI是一个很广的概念,只要是能理解物理规则的AI,都是Physical AI。
而具身智能(Embodied AI)是其中的一个关键细分领域,它不仅关注AI本身,还强调AI要依托于一个能够与环境互动的“身体”上 ,比如机器人就是具身智能的一种。
具身智能的核心在于“感知-决策-行动”的闭环,这就是业界常说的"VLA(Vision-Language-Action,视觉-语言-动作)"模型。
一个具备通用能力的具身智能体,不仅需要一个像VLA这样强大的“大脑”,还需要一个高度灵活的“小脑”来控制精细动作,以及一个稳定、灵活、适应性强的身体。
这种智能的机器人才能够从只能在封闭环境下完成预设动作,到真正在开放环境中(如杂乱的厨房、动态的街道)中完成更复杂和动态的任务。
国际公司
2025年,具身智能正式进入商业化元年,国际上有很多科技大厂都在布局。
特斯拉要将人形机器人Optimus,作为支撑未来特斯拉价值的核心支柱,长期收入预测10万亿美元。
而Gogole DeepMind的Gemini Robotics展示了顶级AI Lab在泛化能力上的统治力 。
Figure AI和OpenAI合作,在宝马工厂里部署了机器人。
中国公司
中国在机电一体化和机器人硬件供应链方面有着得天独厚的优势。无论是传感器、电机还是整体制造能力,中国公司表现出了惊人的迭代速度。
在AI领域,全球又是中美在角逐,尤其在机器人领域,中国相比美国有供应链的优势。
摩根士丹利报告显示,中国在人形机器人产业供应链中占据了63%的主导份额,其中在“身体”环节的集成能力达到45% 。核心零部件如伺服电机(占比19%)、减速器(占比14%)已实现大规模国产替代 。
中国也有非常多的具身智能创业公司,比如自变量机器人其中头部的一家。
继获得顶级创投、美团、阿里云投资之后,2026年1月12日,自变量宣布完成新一轮融资,XXXX,这是三家大厂首次共同押注一家具身智能创业公司,足以看出巨头对这一赛道的重视。
自变量
自变量成立于2023年底,在成立之日起就坚定选择了“端到端统一VLA大模型”的技术路线。
传统的机器人系统通常是分级的、模块化的,比如有专门的视觉模型来看东西,有语言模型来听指令、规划算法算路径,最后再控制器电机去行动。
而所谓的端到端(End-to-End)VLA模型,不再做这些区分,而是将所有的信号,包括视频流、语言,一起输入给模型,模型直接产生需要执行的动作。
自变量机器人在2023年的时候,就选择“端到端统一VLA大模型”的技术路线,是非常具有前瞻性的。
一年后,美国公司Physical Intelligence(PI)的模型发布,VLA才成为了行业的主流路线。
自变量在2024年10月训练出最大参数规模的具身智能通用操作大模型,Great Wall系列WALL-A模型公开多种操作Demo动作达到世界一流水平。
然后在2025年9月,自变量机器人正式开源了端到端具身智能基础模型WALL-OSS,开源首日即吸引了众多具身智能领域开发者关注及技术咨询。自变量机器人要通过开源来构建开发者生态、聚集培养人才,加快技术迭代。
今年3月,Google Gemini robotics公布了他们的进展,也是类似的做法:any-to-any和COT。最近Physical Intelligence(PI)新发布的π0.5也做了类似的事情。所以实际上我们非常早地就预判到了技术进步的方向,和PI等国外玩家做这个事的时间差不多。
所以我们敢说我们的模型水平基本上和PI、和google在同一个水平线上。因为的确是在相近的时间做出了类似的事情,达到了类似的效果。而国内厂商普遍才刚起步要往这个方向去做,进度上就会差得比较多了。
与传统将任务拆解为“感知-规划-控制”的方案不同,该公司坚持完全端到端的技术路线,其核心产品 WALL 系列(Great Wall) 基础模型直接将视觉信号映射到动作指令。
Nvidia: What is Physical AI?
Physical AI lets autonomous systems like cameras| robots| and self-driving cars perceive| understand| reason| and perform or orchestrate complex actions in the physical world.
Physical AI is unlocking new capabilities that will transform every industry. For example:
Robots: Physical AI elevates robots from rigid automation to true autonomy. Enabling them to sense| reason| and act in real time helps them perform with greater safety| precision| and adaptability in any environment.
- Autonomous Mobile Robots (AMRs) in warehouses can navigate complex environments and avoid obstacles| including humans| by using direct feedback from onboard sensors.
- Manipulators| or robot arms| can adjust their grasping strength and position based on the pose of objects on a conveyor belt| showcasing both fine and gross motor skills tailored to the object type.
- Surgical robots benefit from this technology by learning intricate tasks such as threading needles and performing stitches| highlighting the precision and adaptability of physical AI in training robots for specialized tasks.
- Humanoid robots—or general-purpose robots—need both gross and fine motor skills| as well as the ability to perceive| understand| reason| and interact with the physical world| no matter what the given task is.
Autonomous Vehicles (AVs): Physical AI lets AVs process sensor data in real-time to perceive and understand their surroundings. Reasoning vision-language-action (VLA) models use this data to make informed decisions in various environments| from open freeways to urban cityscapes. Training AVs in scalable| physically accurate simulation environments helps them more accurately detect pedestrians| respond to traffic or weather conditions| and autonomously navigate lane changes| effectively adapting to a wide range of unexpected scenarios.
Smart Spaces: Physical AI is enhancing the functionality and safety of large indoor and outdoor spaces like factories and warehouses| where daily activities involve steady traffic of people| vehicles| and robots. Using fixed cameras and advanced computer vision models| teams can enhance dynamic route planning and optimize operational efficiency by tracking multiple entities and activities within these spaces. Video analytics AI agents further improve safety and operational efficiency by automatically detecting anomalies and providing real-time alerts.
Vision-Language-Action (VLA)
Vision-Language-Action (VLA) 模型是具身智能(Embodied AI)领域的前沿技术架构。它打破了传统机器人“感知-规划-控制”分离的模式,将视觉感知、语言理解与物理操作指令统一在单个端到端的大模型框架中。
一、 什么是 VLA 模型?
VLA 模型是一种多模态基础模型。其核心逻辑是将机器人的“动作”(Action)视为一种特殊的“语言”:
- 输入(Input): 实时图像/视频流(Vision)+ 自然语言指令(Language)。
- 处理(Process): 通过视觉编码器和语言模型(LLM)骨干,对环境和任务进行语义和空间的深度对齐。
- 输出(Output): 直接生成低级机器人控制指令(Action Tokens),如关节速度、末端位姿或抓取力度。
技术本质: 通过在海量互联网数据(图片-文本)和机器人轨迹数据(图片-文本-动作)上联合训练,使模型具备“互联网规模的常识”并能将其转化为物理世界的精准操作。
二、 目前技术现状 (截至2026年初)
VLA 技术正处于从“实验室Demo”向“工业级可靠性”跨越的转折点。
代表模型
| 代表模型 | 发布机构 | 核心突破 |
|---|---|---|
| RT-2 (Robotics Transformer 2) | Google DeepMind | 首个展示互联网规模泛化能力的 VLA,能理解“拣选那个最像恐龙的玩具”这类抽象指令。 |
| OpenVLA | UC Berkeley 等 | 首个高性能开源 VLA(7B 参数),基于 Prismatic 架构,支持在不同品牌机械臂上跨平台微调。 |
| π0 (Pi-Zero) | Physical Intelligence | 引入扩散策略(Diffusion Strategy),解决了传统自回归模型在处理连续、高频动作时的不平滑问题。 |
| GR00T N1.6 | NVIDIA | 专为人形机器人设计的推理型 VLA,支持全身协同控制,并集成了“思维链”推理过程。 |
| Alpamayo 1 | NVIDIA | 针对自动驾驶领域的推理型 VLA,能生成决策逻辑轨迹图(Reasoning Traces)。 |
最新技术趋势:
- 推理增强(Reasoning-VLA): 不再仅是“看图说话做动作”,而是先生成逻辑步骤(如“先移开杯子,再拿下面的垫子”),再执行动作。
- 跨机器人泛化: 模型开始支持“一次训练,多机部署”,同一套 VLA 可以在宇树、Figure 或 Boston Dynamics 的硬件上运行。
三、 面临的挑战
尽管进展迅速,VLA 仍面临三大“死亡谷”:
- 数据孤岛与稀缺性: 互联网有无穷的文字和图像,但高质量的“机器人操作轨迹数据”极度匮乏。
- 动作频率与延迟: LLM 的推理速度通常难以满足机器人 100Hz 以上的实时控制需求,高频微操与大模型推理之间存在天然矛盾。
- Sim2Real(仿真到现实)的鸿沟: 仿真中 100% 成功的 VLA,在现实中常因光影变化、微小摩擦力差异或感知噪声而失效。* 长程任务崩溃: 当任务链条过长(超过30秒的操作),VLA 容易出现“记忆漂移”或陷入无效循环。
四、 商业化公司与阵营
VLA 领域的商业竞争主要集中在“模型提供商”与“硬件集成商”之间。
模型与平台领先者
- NVIDIA (英伟达): 提供全栈工具链。最新发布的 Cosmos 物理 AI 平台和 Isaac Lab-Arena 已成为行业标准,其 GR00T 模型正被多家机器人公司集成。
- Physical Intelligence (Pi): 创始团队来自 OpenAI、DeepMind,旨在打造“通用的物理大脑”,其
模型是目前最接近通用的控制引擎之一。 - Google DeepMind: 依托 RT 系列模型和 Gemini 的多模态能力,在研究领域保持绝对统治力。
具身智能硬件巨头 (集成 VLA)
- Figure AI: 与 OpenAI 深度合作。其 Figure 02 机器人在 BMW 工厂已开始实地测试。
- Tesla (特斯拉): 其 Optimus 机器人内部集成了类似 VLA 的端到端神经网络,主要用于工厂内部组装。
- AGIBOT (智元机器人): 中国领先的具身智能公司,已推出集成推理 VLA 的工业人形机器人。
- Boston Dynamics: 旗下的 Atlas 已从液压转为全电动,正通过 NVIDIA 的技术栈大规模引入 VLA 进行复杂环境作业。
Embodied vs. Disembodied AI
Embodied vs. Disembodied AI: Two Paths| One Question
Disembodied AI(也称为非具身AI)是指人工智能系统不依赖物理身体或实体形式,主要通过抽象的符号处理、数据计算和模拟进行认知和决策。这种AI通常运行在数字环境中,不直接感知或与物理世界互动。
典型例子:大型语言模型(如ChatGPT)、知识引擎、规划系统或棋类AI(如Deep Blue),这些系统基于静态数据或离线模拟运作,而不涉及传感器输入或物理动作。
证据来源:学术综述(如arXiv:2407.06886)明确区分“cyber space中的disembodied AI”和物理空间中的embodied AI;Frontiers in Artificial Intelligence期刊论文(2023)将disembodied AI描述为无法真正理解人类具身互动的程序。
Embodied AI(具身AI)是指人工智能系统集成到物理实体(如机器人)或虚拟代理中,通过传感器感知环境、执行动作,并从物理互动中学习和适应。这种AI强调身体(embodiment)在智能形成中的作用,智能从感知-行动循环中涌现。
典型例子:自主机器人、无人机或虚拟化身,能够实时感知环境、导航并执行任务。
证据来源:NVIDIA官方术语表定义为“将AI集成到物理系统中,使其与物理世界互动”;TechTarget(2024)和多个学术论文(如arXiv:2505.14235)将embodied AI描述为通过身体与环境互动的学习系统,与disembodied AI形成对比。
二者区别:
Disembodied AI 侧重抽象推理和数据驱动,独立于物理形式;Embodied AI 依赖物理或模拟身体,通过动态互动获取经验。
学术观点(如Human Brain Project报告,2023)认为embodied AI可能更接近人类级认知,而disembodied AI在理解物理世界方面存在根本限制(如无法体验传感器-动作反馈)。
这些定义来源于同行评审论文、行业报告和学术综述(如Wiley期刊2025审稿、Springer出版物),无虚构数据。
奥比中光
上游供应商 奥比中光: https://www.orbbec.com.cn/。
奥比中光科技集团股份有限公司(688322.SH)是行业领先的机器人视觉及AI视觉科技公司,致力于构建机器人与AI视觉产业中台、打造机器人的“眼睛”。
基于自研芯片和全栈式系统技术,奥比中光为机器人、3D扫描、生物识别等行业客户及全球开发者提供高性能的3D视觉传感器及机器人与AI视觉方案,助力新兴行业释放价值、推动传统行业智能化升级。拥有自建生产基地,奥比中光具备百万级量产能力,提供灵活可靠的ODM/OEM 服务。
奥比中光为全球超过3000家客户与开发者提供“研发+制造”的一站式产品和服务,其中机器人视觉业务在中国服务机器人市场占有率超过 70%。
奥比中光成立于2013年,总部位于深圳,在佛山、上海、西安,美国均设有分支机构。2022年7月在科创板上市,获称“3D视觉第一股”。
公司创始人: 黄源浩 奥比中光董事长兼CEO
奥比中光科技集团股份有限公司创始人、董事长兼CEO,3D光学测量专家|于2013年回国在深圳创办奥比中光。
黄源浩本科、硕士、博士分别毕业于北京大学、新加坡国立大学、香港城市大学,并在新加坡、中国香港、加拿大、美国等多个著名课题组开展博士后研究工作,包括麻省理工学院SMART研究中心3D光学系统组,参与出版专著两部,在Optics Letters等著名期刊发表论文20余篇。
竞争对手
中国竞争对手
- Mech-Mind:专注于工业3D视觉和AI解决方案,提供高精度3D相机和机器人引导系统。主要应用于物流和制造业。
- Lanxin Robotics:提供机器人视觉硬件和软件集成,强调自主移动机器人(AMR)和3D感知。
- RobotAI:AI驱动的机器人视觉公司,开发3D扫描和识别技术,针对服务机器人和智能硬件。
- RoboSense:激光雷达和3D感知专家,虽侧重LiDAR,但与Orbbec在机器人视觉重叠,尤其在自动驾驶和机器人导航。
国际竞争对手
- Intel RealSense(现独立运营,原Intel子公司):提供深度相机和3D视觉模组,广泛用于机器人和AR/VR。2025年后独立运营,竞争焦点在消费级和工业级3D传感器。
- Luxonis:专注于AI边缘计算和3D相机(如OAK系列),强调低功耗和实时处理,适用于无人机和机器人。
- Zivid:挪威公司,提供高分辨率3D相机,针对工业自动化和拾取任务。
- Photoneo(已被Zebra Technologies收购):斯洛伐克公司,开发3D视觉系统,强于复杂环境下的物体识别。
- Cognex:美国机器视觉巨头,提供2D/3D视觉软件和硬件,市场份额大,应用于质量检测和机器人引导。
- Keyence:日本公司,高端机器视觉传感器供应商,强调高精度和易用性。
- Basler:德国相机制造商,提供工业级3D相机和视觉系统。
- OMRON:日本自动化巨头,集成机器人视觉解决方案。
- Teledyne和SICK:美国/德国公司,专注于工业传感器和3D视觉,强于制造业应用。
- Pickit 3D和SensoPart:欧洲公司,提供3D拾取和视觉引导系统。
| 公司名称 | 上市状态 | 主要股票代码 | 交易所 | 备注 |
|---|---|---|---|---|
| Cognex | 已上市 | CGNX | NASDAQ (美国) | 机器视觉巨头 |
| Keyence | 已上市 | "6861 (日本本土) KYCCF (ADR)" | "东京证券交易所 OTC (美国)" | 日本精密制造领先 |
| Basler | 已上市 | BSL | 法兰克福证券交易所 (德国) | 工业相机制造商 |
| OMRON | 已上市 | "6645 (日本本土) OMRNY (ADR)" | "东京证券交易所 OTC (美国)" | 自动化巨头 |
| Teledyne | 已上市 | TDY | NYSE (美国) | 包含机器视觉业务 |
| RoboSense | 已上市 | 2498.HK | 香港交易所 | 中国LiDAR与3D感知公司 |
X Square Robot
自变量机器人科技有限公司 (X Square Robot) 是目前中国乃至全球具身智能(Embodied AI)与 VLA 模型领域的顶尖初创企业之一。
基于 2024 年至 2026 年初的公开技术进展、融资数据和行业评测,自变量机器人的行业地位可以从以下四个维度进行客观剖析:
一、 技术地位:端到端 VLA 路线的先驱
自变量机器人被公认为国内最早实现端到端通用具身大模型的公司之一。与传统将任务拆解为“感知-规划-控制”的方案不同,该公司坚持完全端到端的技术路线,其核心产品 WALL 系列(Great Wall) 基础模型直接将视觉信号映射到动作指令。
- WALL-A 模型: 该公司自研的统一 VLA 基座模型,号称是目前最大规模的端到端具身智能模型之一。其核心优势在于处理高度随机性的物理环境和精细化操作(如操作易碎品、穿针引线等)。
- 开源贡献: 2025 年发布的 WALL-OSS(Open Source Series)是行业内具有影响力的开源物理世界基础模型,具备 VLA 控制能力和“思维链”(Chain-of-Thought)推理能力,能够拆解长序列复杂任务。
- 技术架构: 采用共享注意力(Shared Attention)+ 任务路由 FFN 结构,类似于 Physical Intelligence 的
架构,解决了自回归模型在高频实时控制中的平滑度难题。
二、 商业化现状与资本认可
自变量机器人在资本市场处于“第一梯队”,其融资规模和背后的资方反映了其高度的行业确定性。
- 融资级别: 截至 2025 年底,累计融资金额已超过 10 亿人民币(约 1.4 亿美元),完成 A+ 轮融资。
- 核心股东:
- 阿里云: 2025 年 A+ 轮由阿里云领投,这是阿里云首次在具身智能领域进行大额领投。
- 美团: 美团战投连续多轮追投,显示出其在生活服务、物流末端场景落地的深度绑定意图。
- 顶级风投: 红杉中国、联想之星、君联资本、九合创投等。
- 量产节点: 计划于 2025-2026 年间开始小批量交付其旗舰产品 Quanta X2(双臂滚轮人形机器人),目标场景涵盖物流、养老和商业服务。
三、 核心产品矩阵
| 产品系列 | 定位 | 技术特征 |
|---|---|---|
| WALL-A | 软件大脑 (VLA Foundation Model) | 具身智能通用大模型,支持跨形态机器人适配。 |
| Quanta X1 | 轮式双臂机器人 | 侧重于移动操作任务,已在多个实验性场景完成闭环。 |
| Quanta X2 | 人形/类人移动平台 | 旗舰级硬件,集成 VLA 驱动的全身协同控制(Loco-manipulation) |
四、 行业评价与挑战 (客观视角)
- 竞争地位在国际上,自变量机器人常被拿来与美国的 Physical Intelligence (Pi) 和 Figure AI 比较。
其独特地位在于:它是 少数几家能够同时自主研发大模型算法(大脑)和自研适配硬件(身体) 的公司之一。
- 面临的挑战数据护城河:
- 尽管 WALL 模型表现优异,但要达到人类级的泛化能力,仍需积累更高密度的物理交互数据(Robot Data Scaling)。
- 硬件稳定性: VLA 模型对硬件的响应频率要求极高,大规模部署时硬件的耐用性和一致性仍待市场验证。
- 场景渗透: 美团的领投预示了配送/服务场景,但这些场景对安全性和长程稳定性(Long-horizon tasks)的要求近乎苛刻。
总结: 自变量机器人目前处于具身智能领域的全球准一线地位。它是中国 VLA 技术路线的坚定推动者,通过 “开源基础模型 + 自研硬件” 的策略,正在建立其技术壁垒。
2025-11-3 这家公司成立两年,获8轮融资,美团、阿里云重仓押注
2024年10月,自变量推出具身智能通用操作大模型Great Wall系列(GW)的WALL-A模型。同月底,由斯坦福、伯克利教授及前Google研究员成立的Physical Intelligence(PI)也推出了其首个端到端VLA模型π0,这让大家看到了端到端是一个大趋势。“我觉得那个时候大家开始批量性地转向我们的技术方向。我们公司本来就在这个方向,也因此受到了更多(尤其是资本市场)的关注和认可。”王潜说。
2025年9月,自变量机器人正式开源其端到端具身智能基础模型WALL-OSS。据杨倩透露,开源首日即吸引数百名具身智能领域开发者关注及技术咨询。目前,团队已建立起持续运营的开源社群,他们试图通过这一举措引领构建开发者生态、聚集培养人才,强化技术迭代。
公司成立初期,自变量主要依赖供应链企业的硬件设备支持模型研发与实验。随着公司的发展,团队逐渐意识到,机器人真正落地与模型规模扩展,离不开硬件能力的支撑。软件和模型决定了智能的上限,而硬件则决定了落地的基础。
杨倩举例,2024年9月,团队已能用模型初步演示“刷马桶”等任务,但在实际落地时,包括末端执行器的负载能力、执行频率、移动底盘与上半身的协同控制、防水性能以及灵巧手操作硬件方面出现诸多问题,当时市场上也缺乏成熟的灵巧手产品,限制了模型的表现。
基于这些现实挑战,自变量从2024年下半年起开始规划自研硬件,量子1号机器人的框架初步搭建于同年11月,后续持续进行了升级迭代。在这期间,自变量团队更加明确了软硬一体协同发展的战略方向。
8月,自变量发布新一代轮式仿人形机器人“量子2号”。在世界机器人大会(WRC 2025)现场,基于自变量自研的臂手一体外骨骼技术,“量子2号”不仅流畅完成了与观众打招呼、比心、猜拳等交互动作,还展示了其具体应用能力,通过夹持清洁刷与拖布头,量子2号可以实现自旋转及360度全方位清洁。
7月初,在接受《中国企业家》采访时,王潜表示,“公司整体的战略重心并未改变,依然把技术突破与核心模型发展放在第一优先级。但与此前相比,自变量已具备相当的自研硬件基础,包括机器人本体及灵巧手等关键部件已逐步成形。因此,在确保不影响技术主线和长期发展的前提下,团队对商业化持开放态度,并愿意借助现有硬件及模型能力,探索一些可实现的商业应用。”
在商业化路径上,目前自变量将市场划分为科研和商业两大方向。杨倩解释:“在科研市场,我们主要销售硬件本身和综合性解决方案,用户可以根据自身需求调模型、做实验,我们提供的是底层能力。而在行业市场,我们必须带着实际功能进入,真正解决客户的具体问题。”
2025-05-29 自变量机器人王潜:具身智能大模型没法抄国外作业
机器人,是王潜最执着的事。他本硕毕业于清华大学,博士就读于美国南加州大学,曾在美国创立量化基金公司。但在做量化之后,他却“好一阵子整晚睡不着,后悔没把机器人事业做下去”
一位双币机构投资人告诉智能涌现,从融资金额看,目前国内人形机器人创业公司已经形成了鲜明的梯队。第一梯队的公司有三家:宇树科技、智元机器人和银河通用,融资金额都在15亿元以上。自变量机器人融资金额超过10亿元,已经从二线企业进入准一线之列。
他创立的自变量机器人自2023年公司成立之日起就坚定选择了“端到端统一VLA大模型”的技术路线,并以每2-3个月更新一版模型的速度推进研发。
一年后,随着美国公司Physical Intelligence(PI)的模型发布,VLA成为了行业的主流路线。
以前自变量的模型是一个纯粹输出action(动作)的模型,是多模态进,单模态出。从去年10、11月开始,我们开始做any-to-any的模型,是多模态进,多模态出,除了输出action(动作),也可以输出语言和视觉等。
在全模态融合的框架下,自变量也做很长的COT(思维链)。差不多就在这两次融资之间,我们把思维链做出来了。
今年3月,Google Gemini robotics公布了他们的进展,也是类似的做法:any-to-any和COT。最近Physical Intelligence(PI)新发布的π0.5也做了类似的事情。所以实际上我们非常早地就预判到了技术进步的方向,和PI等国外玩家做这个事的时间差不多。
所以我们敢说我们的模型水平基本上和PI、和google在同一个水平线上。因为的确是在相近的时间做出了类似的事情,达到了类似的效果。而国内厂商普遍才刚起步要往这个方向去做,进度上就会差得比较多了。
补充一下,端到端路线也有两种不同的做法,一类是像Figure的两层模型路径:high level的VLM来做reasoning、planning,low level的VLA来做实际的动作生成部分;另一类做法就是不作区分,一体式的端到端。
我们早期也尝试过两层模型,但发现单层模型的天花板明显高于两层的,所以自变量倾向于统一的端到端范式。
《智能涌现》:现在自变量的具身智能模型能力,如果类比AI大模型,处于哪个阶段?
王潜:我觉得还处于GPT-2的阶段,GPT-3当时有一些明显的特征,是在我们今天的模型上没有足够的scale去达到的。业内像PI和google的进度也差不多,这是由Scaling Law的客观规律决定的。
《智能涌现》:国内具身智能大模型要实现商业化还需要多长时间。
王潜:其实基本上快的话就是一年左右的时间点,慢的话可能就是两年左右。我指的是真正的商业化,能够实际意义上的让用户愿意去付费。当然商业化也分不同阶段,要进入C端,比如家庭的保姆机器人或者室内服务机器人,时间要更慢一些,可能是3-5年。
大家普遍是会高估短期的技术进步,低估中长期的技术进步——它比大家想象的会快一些。
《智能涌现》:到现在这个估值体量,投资人现在会对自变量有商业化的要求吗?
王潜:分投资人。有的投资人比较看重具身智能模型能力可以达到多高的上限,另一部分投资人比较看重商业化,不同投资人的偏好风格差距还是挺大的。
自变量有些特殊,不谦虚地说,我们就是处于国内具身智能模型领先地位的,投资人对于第一名天然是有一些优待。大家相信我们能够达到非常高的upside,所以不会要求我们为商业化而商业化,大家更希望我们去做“有价值”的商业化,希望我们更加专注通用具身智能模型的大目标。
《智能涌现》:今年底或明年初就完成POC进入实际应用的话,会是一个什么样的利润率水平。
王潜:传统的服务机器人能做的事情比较单一,而我们的机器人是通用的,机器人能力不同,创造的价值不同,市场竞争态势和客户的付费意愿也不同。当然早期阶段盈利并不是最重要的目标,主要还是希望通过理解实际场景的需求打磨产品。
科研和迎宾这两个场景本身市场总规模不大,不可能当做具身智能最终面向的目标市场。这两个场景可以作为“沿途下蛋”的产物,但如果把它作为一段时间的主要方向,就可能偏离最终的目标。
《智能涌现》:这两个场景确实规模不大,但是不是也有可能和其他小场景共同造出一个不大不小的市场来,足够让一家公司做到上市体量,比如某公司的投资方说过,“仅来自股东方的需求可能就创造出几万台机器人的销量”。
王潜:问题是这种上市有什么意义呢?这几万台做完了之后呢?不能说这几万台的需求做完之后,就不做生意了。
《智能涌现》:如果具身智能比AGI更难,永远实现不了,抓住科研和迎宾这种小市场,是不是一种务实?
王潜:我觉得大可不必,如果创业者不相信具身智能,为什么要去做呢?如果认为具身智能是非常遥远、几十年后才会出现的事情,那根本就不应该现在进入这一领域。
《智能涌现》:你怎么看工厂场景?最近Figure被外媒报道,Figure的人形机器人在宝马工厂里打工的事情有夸大的嫌疑。
王潜:现在人形机器人进工厂,能落地的事情非常有限,其实就是一个PR(公关)行为。
实际工厂对速度和准确率有很高的要求,很多公司目前在做的任务其实还是更适合用上一代技术来实现。
比如流水线相对来说,还是一个比较封闭、固定的环境,反而不利于发挥具身大模型所追求的复杂操作,开放、随机、动态环境和场景、泛化性的要求等,具身机器人在一般的工厂场景里也学不到什么,场景太简单了,对于模型能力提升帮助非常有限。
自变量更倾向于选择复杂的场景,复杂场景才能真正促进模型能力有效提升,也是真正意义上存在客户需求、用户愿意买单、替代完成人类不愿意做的事情的领域。
经济学中一直有所谓是需求创造供给,还是供给创造需求的争议,在具身智能这一Moonshot领域,是很明显的供给创造需求。
《智能涌现》:美国同行的估值更高,资金更多,中美之间的具身智能模型水平是不是有差距?
王潜:国内的整体水平相比于国外肯定还是差的,而且差得不少。我们重点关注的国外同行包括Physical Intelligence(PI)、google、特斯拉。
但就目前来说,我们还是有很大的机会能够和美国在同一个水平线上去发展。甚至我们有机会在今年或者明年超过他们。
我觉得大家会有觉得国内做的不如美国的心态,可能和过去长期处于“跟随者”的角色有关。但在具身智能的发展实际中,没必要过于自我怀疑。以自变量为例,我们能做到的模型水平已经能够和PI等国际顶级团队在同一个水平线上,在部分指标上甚至实现了超越。
《智能涌现》:第一梯队的PI已经开源了机器人通用基础模型π0,这会不会把大家的水平拉平?
王潜:PI开源到现在差不多半年的时间,国内有一些企业也尝试在其基础上进行微调,但从实际效果来看,并不会明显优于其他开源方案,更无法完整复现PI团队在其自有机器人本体上的表现。实际上,跨本体适配的问题依然是一个重要挑战。
《智能涌现》:PI的π0微调之后,可以应付什么样的商业化场景?
王潜:目前来看,在新本体上微调后π0的能力会有比较大的损失,在商业化场景中的实际应用比较有限。实际上PI之所以选择开源,很大程度上在于其自身难以直接商业落地。PI本身并不做硬件,需要依赖其他企业将模型和硬件结合来落地,所以它才会采取开源模型这样的方式。
第二,具身智能这个领域还是有特殊性。比如A实验室开源了一个具身智能模型,全世界没有任何一个实验室能够100%的复现出来开源实验室在他们自己环境下能做到的东西。不要说完整的复现,哪怕是大部分的复现也都很难实现。语言模型可以去蒸馏,但在硬件领域,不可能脱离机器人把数据蒸馏出来。
2025-10-22 美团积极构建机器人“盟友圈” 具身智能加速从实验室冲向商业战场
更引人关注的是,年会现场,宇树科技创始人王兴兴、自变量机器人CEO王潜和星海图智能联合创始人许华哲等美团投资过的具身智能企业代表集体亮相,与美团同台探讨商业化路径。
“2030年,我们预判将是具身智能的时代。今天,我们站在一个新的时代的开启,也会展望未来10年到20年的剧情逐渐揭开。”毛一年表示。
这两年来,美团在具身智能领域频繁出手,仅是今年,美团龙珠和美团战投就先后投资星迈创新、星海图、自变量机器人、妙动科技、康诺思腾等具身智能和机器人公司。
今年7月,美团以领投方身份相继投资了它石智航和星海图,其中它石智航累计融资达2.42亿美元,创下中国具身智能行业天使轮融资纪录。至此,美团在机器人领域形成了涵盖宇树科技(机器人本体)、银河通用(通用机器人平台)、自变量机器人(特定场景应用)等企业在内的完整投资矩阵。
然而,当前的具身智能赛道已呈群雄逐鹿之势,阿里、京东在机器人领域深度布局。今年5月以来,京东先后宣布了对帕西尼、智元机器人、逐际动力等企业的投资,实现在具身智能领域“六连投”。字节跳动也通过投资清洁机器人等细分领域积极卡位。除此之外,极智嘉、快仓等专业机器人公司在特定领域已建立起相当的技术壁垒。
对于美团在具身智能和科技创新领域的投资,互联网分析师尹生此前向《每日经济新闻》记者表示,美团投资这些先进领域既能补充现有业务,也看中这些赛道作为独立市场的巨大空间。
“通过投资这些领域去进行全球化的布局和探索,比本地生活业务的全球化更明智一些。”尹生提到,美团可能也有机会在这些新的产业中找到建立第二增长曲线的机会
2025-10-9 阿里的具身智能逻辑:广泛布局“躯体”后,终于要跟“大脑”融合了
在这条赛道上,早已巨头林立,模式各异:特斯拉正以“从芯片到整机”的全栈自研模式打造擎天柱(Optimus);明星创业公司Figure AI选择与OpenAI结盟,构成“顶尖AI大脑+敏捷硬件身体”的典型组合;而Google DeepMind则持续通过发布RT系列模型,探索通用AI模型控制万物的技术边界。
就在林俊旸官宣的同一天,日本软银集团也正式宣布,以近54亿美元现金,将工业机器人“四大家族”之一ABB集团旗下的“机器人与离散自动化事业部”收入囊中。软银董事长孙正义对此明确表示,此举旨在将“人工超级智能和机器人技术相融合”,其战略雄心可见一斑。
东西方两大巨头的同日行动,也再次印证了英伟达CEO黄仁勋在今年6月的判断:AI与机器人是英伟达的两大技术机遇,将带来“数万亿元”的长期增长机会。牌桌上的玩家们已经达成共识:让AI拥有身体,进入物理世界“干活”,是一片巨大的蓝海。